RAGデータベースの選び方 ─ ベクトルDB・グラフDB・ハイブリッド構成を比較
鳥
2026.06.19
BTMAIZ の鳥と申します。
主に、生成 AI 関連や AI 開発ツールについて発信していきます。
RAG とデータベース設計の関係を理解する
RAG(検索拡張生成)とは何か
RAG(Retrieval-Augmented Generation、検索拡張生成)は、大規模言語モデル(LLM)によるテキスト生成に外部データベースの検索を組み合わせることで、出力精度と信頼性を向上させる技術です。LLM は学習データの範囲内でしか回答できませんが、RAG を使うことで社内文書・専門情報・学習後に索引化した最新データといった学習後の知識を参照できるようになります。ファインチューニングなしでドメイン知識を注入できる点が大きな特徴です。
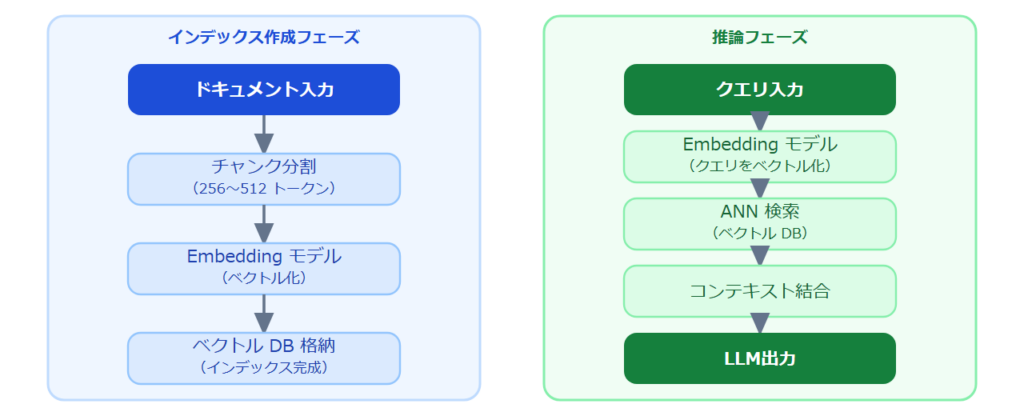
RAG の処理は大きく2つのフェーズに分かれます。まずインデックス作成フェーズでは、ドキュメントをチャンクに分割し、Embedding モデルで Vector 化してデータベースに格納します。次に推論フェーズでは、ユーザーのクエリを Vector 化し、近似最近傍(ANN)検索で類似チャンクを取得、LLM のプロンプトに結合して回答を生成します。このフローの全体像を以下の図に示します。
なぜ DB 設計が RAG の性能を左右するのか
RAG の検索精度・レイテンシ・コストは多くの場合、データベース設計に依存します。どれだけ優秀な LLM を使っても、検索が的外れなコンテキストを返すと回答品質は大きく落ちます。また、Vector DB の選択を誤ると、スケールアップ時にレイテンシが跳ね上がったり、運用コストが想定を大幅に超えたりする事態になりかねません。データベースの設計判断は、RAG システム全体の性能を決定するもっとも重要なアーキテクチャ決定のひとつといえます。
この記事で扱うパターンの全体像
この記事では、RAG のデータベース設計パターンとして以下の3つを取り上げます。まず最も基本となる Vector DB、次に「関係」の多段推論が必要な場面で活きる Graph DB、そして本番環境でよく採用される複数 DB を組み合わせたハイブリッド構成(Polyglot Persistence)です。それぞれの仕組み・向いているユースケース・選定の判断軸を順に解説し、記事の最後に実装で避けるべきアンチパターンをまとめます。
Vector DB ─ RAG の中核ストレージを選ぶ
ANN 検索とは何か ─ 通常 DB と何が違うか
Vector DB は、高次元の Embedding Vector を格納し、クエリ Vector に最も近い上位 k 件を高速で返す専用データストアです。通常のリレーショナル DB は完全一致や範囲検索を得意としますが、標準機能では「意味的に近い文書を探す」という操作には対応していません。なお専用の拡張機能を使えば、既存の RDBMS 上でも ANN 検索が可能です。Vector DB が使う近似最近傍探索(ANN: Approximate Nearest Neighbor)は、厳密な最近傍を探すより精度をわずかに犠牲にすることで、適切なインフラ環境下では、数千万件規模の Vector に対しても数十ミリ秒以内での応答が期待できます。
代表的な ANN インデックスアルゴリズムには HNSW(Hierarchical Navigable Small World)と IVF(Inverted File Index)があります。HNSW は Graph 構造で高い Recall と低レイテンシを両立しますが、インデックス構築に多くのメモリを使います。IVF はクラスタリングベースで省メモリですが、パラメータ調整(nlist / nprobe)が必要です。一般的な本番環境では HNSW が優先して使われることが多いです。
ハイブリッド検索(BM25 + Vector )で本番品質に引き上げる
Vector 検索(Dense Retrieval)だけでは、固有名詞・製品コード・専門用語といったレアトークンの検索精度が落ちやすい問題があります。Dense Embedding はこれらを意味空間に圧縮してしまうためです。BM25 などのキーワード検索(Sparse Retrieval)は正確な語句マッチに強い反面、文脈的な意味を捉えにくい傾向があります。この2つを組み合わせたハイブリッド検索が、プロトタイプから本番品質へ引き上げるための有効なアプローチとして広く採用されています。
統合アルゴリズムとして現在の主流は RRF(Reciprocal Rank Fusion)です。各ランキングリストのランク順位からスコアを計算してマージするため、スコアの正規化問題を回避でき、評価データなしで使えるプラグアンドプレイな手法として広く採用されています。なお、評価データが用意できる場合は加重線形結合など代替手法の方が精度が上がるケースもあります。
主要な Vector DB 製品の多くがハイブリッド検索をネイティブまたはオプションでサポートしています。
Graph DB と GraphRAG ─「関係」が重要なデータへの対応
Graph DB が必要になる場面 ─ マルチホップ推論とは
Vector 検索は「意味的に近い文書を取得する」のに優れていますが、「A という人物は B の会社に勤めていて、B の会社は C という規制を受けている。この規制が A の業務に与える影響は?」というような多段の関係推論(マルチホップ QA)は苦手です。法務文書・規制対応文書・社内ナレッジ Graph など、エンティティ間の関係が複雑に絡み合うデータ構造に対しては、Graph DB を使った GraphRAG アプローチが有効です。
Graph DB はデータを「エンティティ(ノード)」と「関係(エッジ)」として格納し、Cypher や Gremlin などの Graph クエリ言語で多段のトラバーサル(ノードからエッジを辿って隣接ノードへ移動する操作)を効率よく行えます。Vector 検索と組み合わせることで、「意味的に近いエンティティを起点にして関係 Graph を辿る」という高度な検索が可能になります。
GraphRAG の仕組みとコスト感
Microsoft が 2024 年に公開した Microsoft GraphRAG は、LLM を使ってテキストからエンティティと関係を抽出し、Graph を構築します。Leiden アルゴリズムでコミュニティを検出し、コミュニティサマリーを生成することで、大規模文書セット全体を俯瞰するグローバルクエリにも対応します。
一方、インデックス化に LLM 呼び出しを多用するため、使用するモデルや文書規模によってコストが大きく変動します。小規模なドキュメントセットでも数ドル、規模が増えるほど数十ドル以上になることもあるため、事前に試算することが重要です。2024 年末に公開された LazyGraphRAG について、Microsoft の発表によるとインデックスコストをフル GraphRAG の 0.1% まで削減し、グローバルクエリコストを約 700 分の 1 に低減できるとされています。ただし、実際の効果はデータセットやモデルの選択に依存するため、自社環境での検証を推奨します。精度特性もフル GraphRAG とは異なるため、用途に応じた評価が必要です。
VectorRAG か GraphRAG か ─ 判断軸の整理
VectorRAG と GraphRAG の使い分けは、クエリの性質によって決まります。判断の起点は「そのクエリに答えるために、いくつのステップの推論が必要か」です。以下の判断フロー図を参考にしてください。
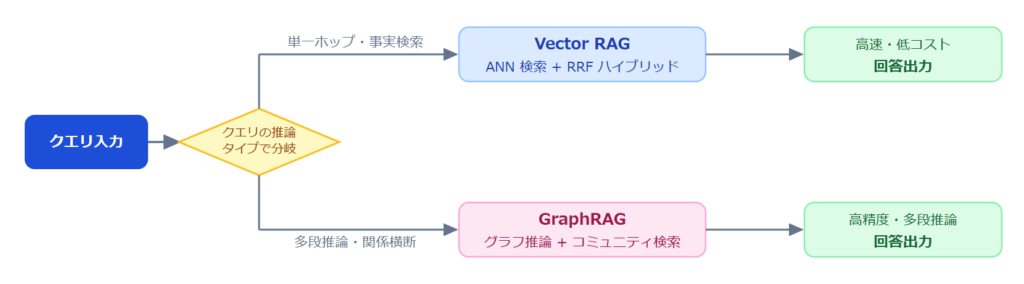
図の上側の分岐(単一ホップ・事実検索)に分類されるのは、「○○とは何か」「△△の概要を教えて」のように、一つのドキュメントや事実を参照すれば答えられる質問です。このタイプには VectorRAG が適しています。ANN 検索で意味的に近いチャンクを高速に取得できるため、レイテンシとコストの両面で有利に働きます。
図の下側の分岐(多段推論・関係横断)に分類されるのは、「A 部門が関与するプロジェクトのうち、B 規制の対象になるものはどれか」のように、複数のエンティティを関係線でたどって初めて答えにたどり着く質問です。VectorRAG は意味的に近い文書を取得することは得意ですが、「関係の連鎖を複数ステップ辿る」ことは苦手です。こうしたケースでは、Graph 構造上でエンティティ間の関係を直接辿れる GraphRAG が力を発揮します。
TIPS: VectorRAG と GraphRAG は二者択一ではなく、両方を組み合わせるハイブリッド構成も有効です。単一ホップのクエリは VectorRAG で高速に処理しつつ、多段推論が必要なクエリだけ GraphRAG に委ねることで、コストと精度のバランスを取ることができます。
実装の進め方としては、まず VectorRAG だけで構築し、「関係を跨いだ質問に答えられない」という課題が具体的に見えてきた段階で GraphRAG を追加するアプローチが現実的です。GraphRAG はインデックス構築に LLM の呼び出しを多用するためコストがかさみやすく、最初から両方を構築しようとすると初期コストが大きくなります。段階的に導入することで、コストを抑えながら必要な精度を確保できます。
ハイブリッド構成(Polyglot Persistence)─ 本番 RAG の実際
なぜ本番では複数 DB が必要になるのか
プロトタイプ段階は単一の DB だけで十分ですが、本番 RAG になると「ユーザーごとのメタデータ管理」「高頻度クエリのキャッシュ」「大規模ドキュメントの格納」「Vector 検索」といった複数の異なる要件が発生します。これらを一つの DB に詰め込もうとすると、役割の混在による複雑化やスケールの壁にぶつかります。
Polyglot Persistence は、役割ごとに最適な DB を使い分けるという設計原則です。このアプローチは現在、本番 RAG の標準になりつつあります。ただし管理対象 DB が増えるため、運用コスト・整合性管理・データ鮮度の計画を設計段階から立てることが重要です。
代表的なハイブリッド構成パターン
本番 RAG で広く採用される構成例と、各 DB の処理フローを以下の図に示します。
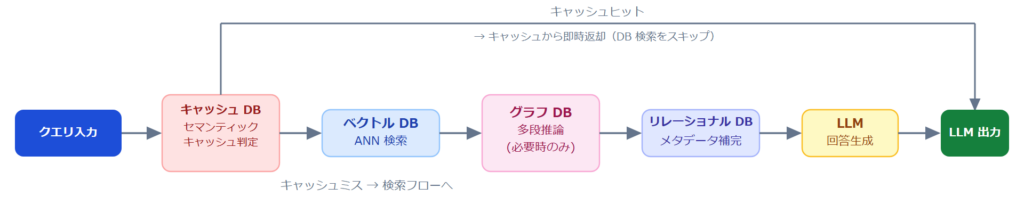
代表的な構成は以下の4層です。
- インメモリキャッシュ DB:セマンティックキャッシュとして高頻度クエリへの即時応答
- ベクトル DB:Embedding 格納と ANN 検索
- グラフ DB(必要時のみ):多段の関係推論が必要なクエリに対応
- リレーショナル DB:ユーザーデータ・ドキュメントメタデータ・フィルタ条件などの構造化データ管理
セマンティックキャッシュで高速化する
インメモリキャッシュ DB のセマンティックキャッシュは、完全一致だけでなく意味的に類似したクエリをキャッシュヒットと判定する仕組みです。「先週の売上を教えて」と「先週の販売実績は?」のような類似クエリに対して、同じキャッシュ結果を返すことができます。Vector DB への問い合わせと LLM 生成を省略できるため、レイテンシとコストの両方を大幅に削減できます。
また、CDC(Change Data Capture)パイプラインを使うことで、既存のデータソースからリアルタイムで Vector DB に同期する構成も取れます。データ鮮度管理は設計段階から計画を立てておくことを推奨します。
実装で避けるべきアンチパターンと本番移行の判断軸
チャンキング設計 ─ 特に影響が大きい設定を正しく決める
チャンクサイズは RAG の検索品質に特に大きな影響を与えるパラメータの一つとされています。一般的な出発点として 256〜512 トークンが広く使われていますが、最適値はユースケースや文書種別によって異なります(事実検索寄りなら 128〜256、技術文書・法律文書なら 512〜1,024 が適するケースもあります)。チャンクが大きすぎると関係のない情報が混入してノイズが増え、小さすぎると文脈が失われます。実務報告ベースでは、1,500 トークン前後の大きなチャンクを 600 トークン程度に縮小してオーバーラップを設けることで、検索精度が大幅に改善したケースが報告されています。チャンキング戦略はセマンティックチャンキングや固定サイズ分割など複数の選択肢があり、どちらが優れるかは文書タイプとクエリパターンに依存するため、実験的に評価することを推奨します。
なお、Late Chunking(文書全体を先に Embed してからチャンク切り出し)などの高度な手法は平均改善幅が約 3% 程度にとどまることが多いようです。まず基本のチャンク設計を最適化することを優先してください。
7大アンチパターンと対処法
以下は RAG 実装でよく見られる7つのアンチパターンです。それぞれの問題点と対処法をまとめます。
| アンチパターン | なぜ失敗するか | 対処法 |
|---|---|---|
| チャンク過大 | 大きすぎるチャンクに関係のない情報が混入し、LLM が正確な回答を生成しにくくなる | 256〜512 トークンを出発点にし、ドキュメント種別や用途ごとに実験して調整する |
| 取得件数不足 | k が小さいままにすると必要なコンテキストが揃わず回答が不完全になる場合がある | 検証で適切な k を決定。汎用的な出発点として 5〜10 を試し、リランキングと組み合わせることで小さい k でも有効なケースがある |
| リランキング省略 | ANN 検索の上位 k 件はスコア順だが、LLM にとって最適な順序とは限らないため回答品質が下がる | Cross-Encoder などのリランキングモデルで上位 k 件を再スコアリングする |
| 出典追跡なし | 引用元を追跡しないと、誤情報が発生した際の原因特定と信頼性担保が困難になる | チャンクにドキュメント ID・ページ番号などのメタデータを付与し、応答に引用元を含める |
| 単一 DB 依存 | Vector 検索のみでは固有名詞・専門用語の検索精度が低く、本番品質に届かない | BM25 + Vector のハイブリッド検索(RRF)を導入する |
| 未評価のチャンク戦略 | チャンキング戦略をデフォルトのまま使い続けると、文書タイプやクエリパターンに合わない分割で精度が低下する | 固定サイズ・セマンティック・ドキュメント構造ベースなど複数の戦略を実験的に評価し、ユースケースに合ったものを選択する |
| 未評価の Embedding | 汎用 Embedding モデルはドメイン固有の語彙・略語・専門用語の表現が弱く検索精度が低い | ドメイン特化モデルを評価し、精度向上が確認できた場合は採用を検討する |
Embedding モデルの選び方と評価
複数のベンチマーク調査によると、ドメイン特化型 Embedding モデルが汎用モデルに対して 10〜30% 程度の検索精度向上が期待できます(ドメインや評価指標によって結果は大きく異なります)。医療・法律・金融など専門性の高い領域では、汎用モデルより特化モデルの採用を検討する価値があります。詳細は参考文献の MTEB 評価結果(https://huggingface.co/spaces/mteb/leaderboard)も参照してください。
Embedding モデルの評価には MTEB(Massive Text Embedding Benchmark) が参考になります。自社ドメインのデータで独自評価セットを作り、実際の検索品質(Recall@k など)を測定することをおすすめします。
コンテキスト長については、使用するモデルのコンテキスト窓の 70〜80% を超えない範囲に収めることを推奨します。長すぎる文脈では、関連情報がコンテキストの中央付近に位置すると LLM が参照しにくくなる「Lost in the Middle」問題が知られています。重要な情報はコンテキストの先頭または末尾に配置し、k 値の設定とチャンクサイズのバランスを取りながら調整してください。
まとめ
3パターンの使いどきを整理する
この記事では RAG のデータベース設計パターンを3つの観点から解説しました。要点を整理します。
- Vector DB:RAG の中核ストレージ。スケールと運用負荷で製品を選ぶ。ハイブリッド検索(BM25 + Vector / RRF)は本番品質への推奨ステップ。
- Graph DB と GraphRAG:多段の関係推論(マルチホップ QA)が必要な法務・規制・ナレッジ Graph 系ドキュメントに有効。単一ホップなら VectorRAG の方が精度が高く、GraphRAG はインデックスコストも大きいため、クエリの性質で使い分ける。
- ハイブリッド構成(Polyglot Persistence):本番 RAG では単一 DB だけでは要件を満たせないケースが多い。リレーショナル DB(メタデータ)・インメモリキャッシュ DB(セマンティックキャッシュ)・Vector DB(ANN 検索)・ドキュメント DB(本文格納)を役割ごとに使い分けるのが現在広く採用されつつあるアプローチ。
段階的に構成を広げるためのロードマップ
実務での判断は「まずスケールと要件を決め、次に既存インフラ資産を確認し、段階的に構成を広げる」という順序で行うことをおすすめします。いきなり複雑なハイブリッド構成を組む必要はありません。プロトタイプはシンプルなシングル DB 構成から始め、スケールアップや本番要件が明確になった段階で専用 VectorDB への移行を検討します。多段推論の必要性が出てきたら GraphDB を追加し、高頻度クエリのキャッシュが課題になったらインメモリキャッシュ DB を組み込む、という段階的な拡張が現実的です。
近年の業界トレンドとして、Vector と Graph を組み合わせたハイブリッド検索が企業向け RAG で注目を集め、採用が拡大しつつあります。まだ普及途上ですが、完璧な設計を最初から目指すよりも、小さく始めて計測しながら拡張していく姿勢が、本番品質の RAG システムを構築する近道の一つといえます。
参考にしたサイト




投稿日2026年06月19日
カテゴリーTech Blog
タグ RAG